

深度学习在美团推荐平台排序中的运用这篇文章写得非常好,但是对于小白的我来说有一些知识点不是那么容易啃,所以在此特意做一个整理,防止自己以后会忘记…本文是对《深度学习在美团推荐平台排序中的运用》的二次加工,里面有我自己对这篇文章的理解,无意侵权,如有违反,我愿意尽快删除。
美团推荐系统面临的挑战
首先美团点出了美团O2O生活服务平台目前在推荐系统中面临的挑战,主要有以下两点:
1. 业务形态多样性:除了推荐商户外,我们还根据不同的场景,进行实时判断,从而推出不同形态的业务,如团单、酒店、景点、霸王餐等。
2. 用户消费场景多样性:用户可以选择在家消费:外卖,到店消费:团单、闪惠,或者差旅消费:预定酒店等。
(在读到这里之前,需要先想想“如果我面临这个问题,我是怎么解决的?我有没有什么更好的解决办法?”)
针对上述问题,美团定制了一套完善的推荐系统框架,包括基于机器学习的多选品召回与排序策略,以及从海量大数据的离线计算到高并发在线服务的推荐引擎。推荐系统的策略主要分为召回和排序两个过程,召回主要负责生成推荐的候选集,排序负责将多个算法策略的结果进行个性化排序。(排序-召回经典的结构不仅适用于IR,同时也适用于推荐系统领域)
召回&排序
召回层:通过用户行为、场景等进行实时判断,通过多个召回策略召回不同候选集。再对召回的候选集进行融合。候选集融合和过滤层有两个功能,一是提高推荐策略的覆盖度和精度;另外还要承担一定的过滤职责,从产品、运营的角度制定一些人工规则,过滤掉不符合条件的Item。
这里提到这召回层的作用:
1. 候选:使用多个召回策略,有多个推荐算法被同时使用,所以对于下文的召回策略来说,美团很有可能同时都在使用。
2. 过滤:从运营的角度过滤掉色情、垃圾商品内容。
下面是一些常用到的召回策略:
- User-Based 协同过滤:找出与当前User X最相似的N个User,并根据N个User对某Item的打分估计X对该Item的打分。在相似度算法方面,我们采用了Jaccard Similarity
- Model-Based 协同过滤:用一组隐含因子(就是embedding啦)来联系用户和商品。其中每个用户、每个商品都用一个向量来表示,用户u对商品i的评价通过计算这两个向量的内积得到。算法的关键在于根据已知的用户对商品的行为数据来估计用户和商品的隐因子向量。
- Item-Based 协同过滤:我们先用word2vec对每个Item取其隐含空间的向量,然后用Cosine Similarity计算用户u用过的每一个Item与未用过Item i之间的相似性。最后对Top N的结果进行召回。
- Query-Based:是根据Query中包含的实时信息(如地理位置信息、WiFi到店、关键词搜索、导航搜索等)对用户的意图进行抽象,从而触发的策略。
- Location-Based:移动设备的位置是经常发生变化的,不同的地理位置反映了不同的用户场景,可以在具体的业务中充分利用。在推荐的候选集召回中,我们也会根据用户的实时地理位置、工作地、居住地等地理位置触发相应的策略。
美团虽然在这里提到了Query-based策略、Location-Based策略,但是并没有提供更多的细节,而这两种策略恰恰回答了美团在开头提出的业务形态多样性和用户消费场景多样性的问题。
排序层:每类召回策略都会召回一定的结果,这些结果去重后需要统一做排序。点评推荐排序的框架大致可以分为三块:
- 离线计算层:离线计算层主要包含了算法集合、算法引擎,负责数据的整合、特征的提取、模型的训练、以及线下的评估。
- 近线实时数据流:主要是对不同的用户流实施订阅、行为预测,并利用各种数据处理工具对原始日志进行清洗,处理成格式化的数据,落地到不同类型的存储系统中,供下游的算法和模型使用。
- 在线实时打分:根据用户所处的场景,提取出相对应的特征,并利用多种机器学习算法,对多策略召回的结果进行融合和打分重排。
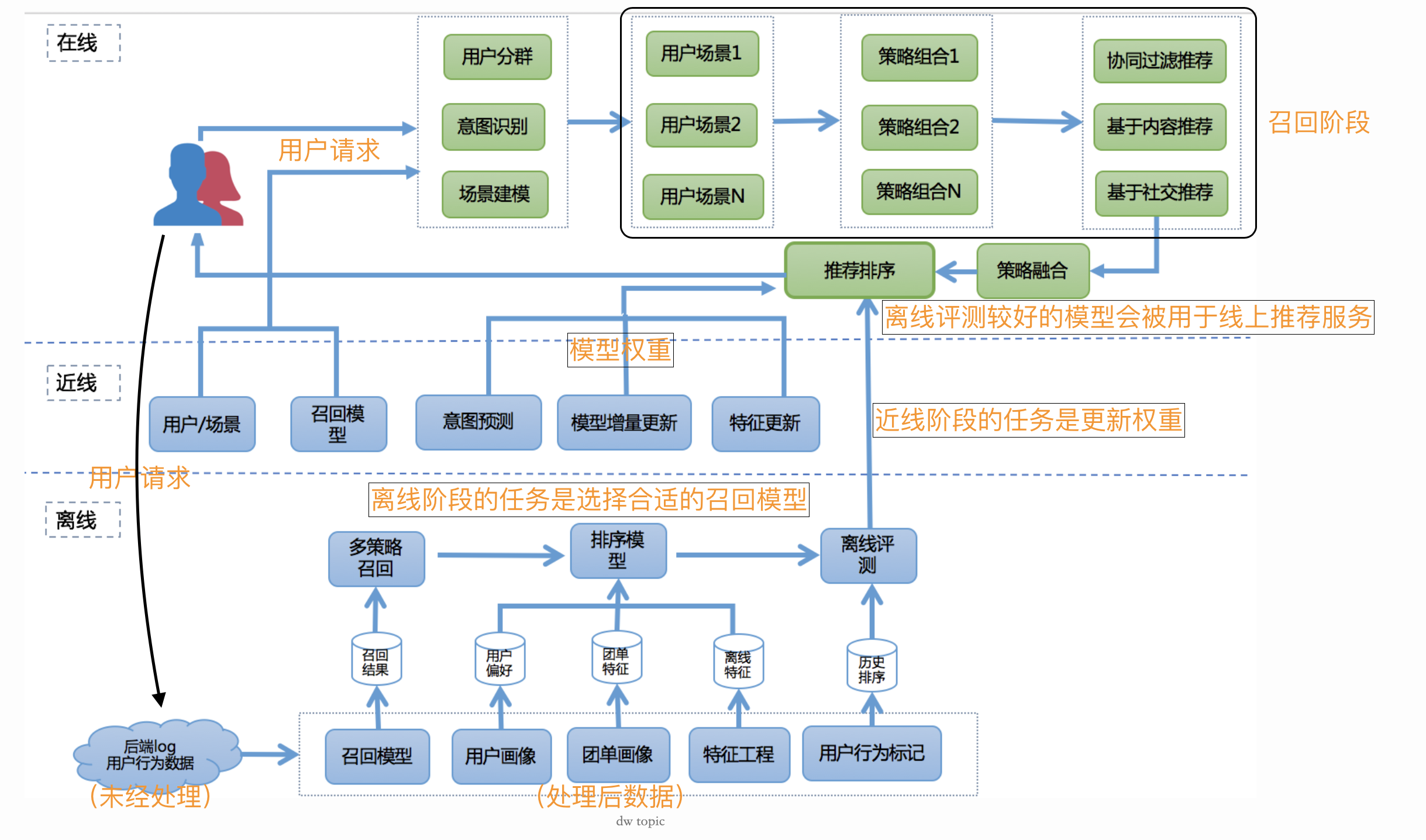
服务架构
下面是推荐服务的系统架构(这里对我来说太重要了,如果掌握得当,自己可以做出一个线上可用的toy性质的推荐系统)

这个图第一次看的时候有些乱,实际上要完全理解这张图,需要一定的知识背景积累,否则看这张图只能是镜中月,水中花,所以美团也给出了一些解释,我也会根据我自己的理解补充一些内容。
从整体框架的角度看,当用户每次请求时,系统就会将当前请求的数据写入到日志当中,利用各种数据处理工具对原始日志进行清洗,格式化,落地到不同类型的存储系统中。在训练时,我们利用特征工程,从处理过后的数据集中选出训练、测试样本集,并借此进行线下模型的训练和预估。我们采用多种机器学习算法,并通过线下AUC、NDCG、Precision等指标来评估他们的表现。线下模型经过训练和评估后,如果在测试集有比较明显的提高,会将其上线进行线上AB测试。同时,我们也有多种维度的报表对模型进行数据上的支持。
对于不同召回策略所产生的候选集,如果只是根据算法的历史效果决定算法产生的Item的位置显得有些简单粗暴,同时,在每个算法的内部,不同Item的顺序也只是简单的由一个或者几个因素决定,这些排序的方法只能用于第一步的初选过程,最终的排序结果需要借助机器学习的方法,使用相关的排序模型,综合多方面的因素来确定。


现有排序框架介绍
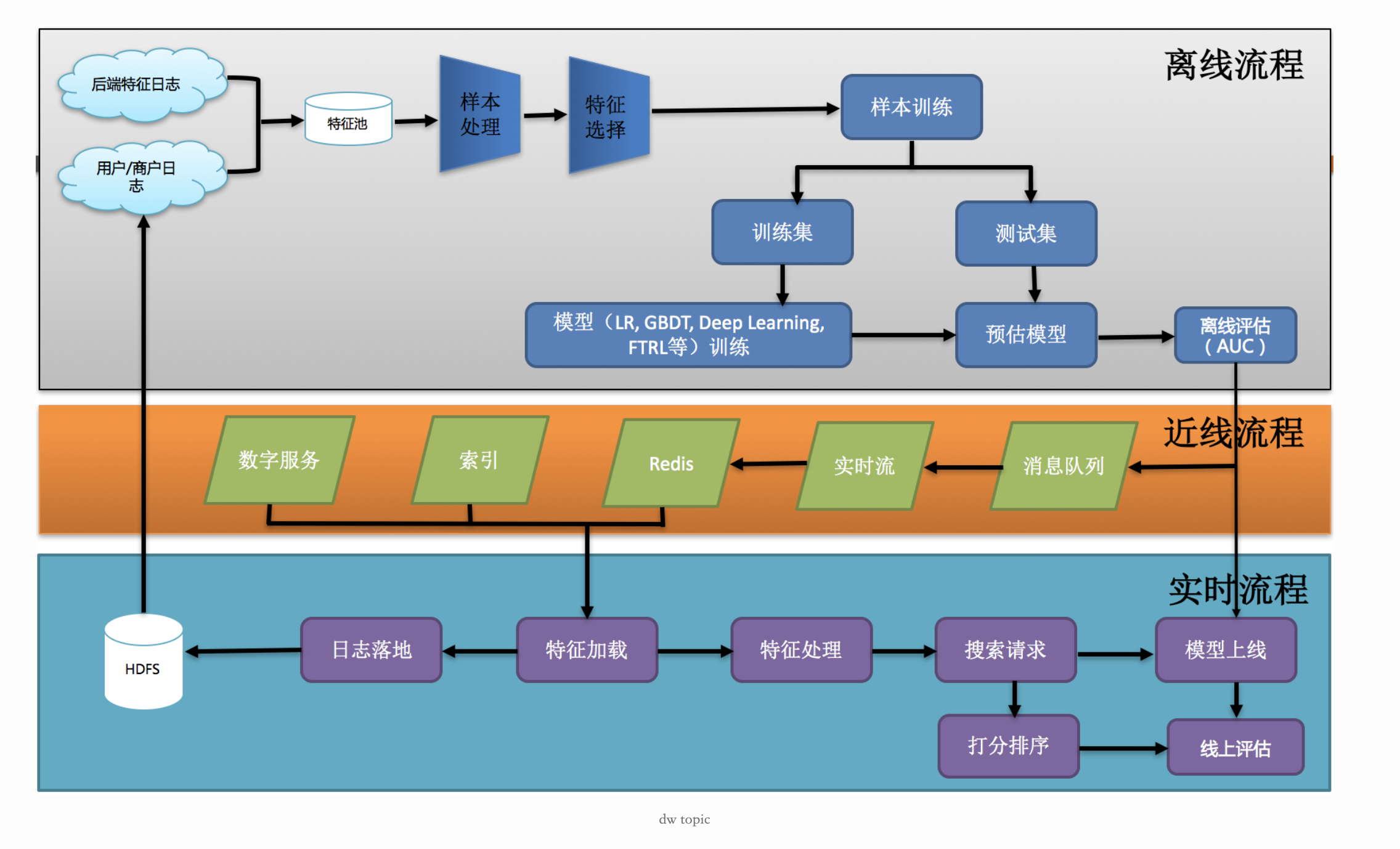
到目前为止,点评推荐排序系统尝试了多种线性、非线性、混合模型等机器学习方法,如逻辑回归、GBDT、GBDT+LR等。通过线上实验发现,相较于线性模型,传统的非线性模型如GBDT,并不一定能在线上AB测试环节对CTR预估有比较明显的提高。而线性模型如逻辑回归,因为自身非线性表现能力比较弱,无法对真实生活中的非线性场景进行区分,会经常对历史数据中出现过的数据过度记忆。下图就是线性模型根据记忆将一些历史点击过的单子排在前面:
在这里提到了线性模型和传统的非线性模型(如GBDT)在线上和线下的比较,在线下非线性模型的得分是比线性模型要高的,但是线上却可能不如传统的线上模型,而线性模型的问题是会出现对历史中出现过的数据过度记忆的问题,所以这两种模型都不是美团在排序推荐上面的最优选择
在这里,美团举了一个线性模型将历史点击过的单子排序在前面的例子:
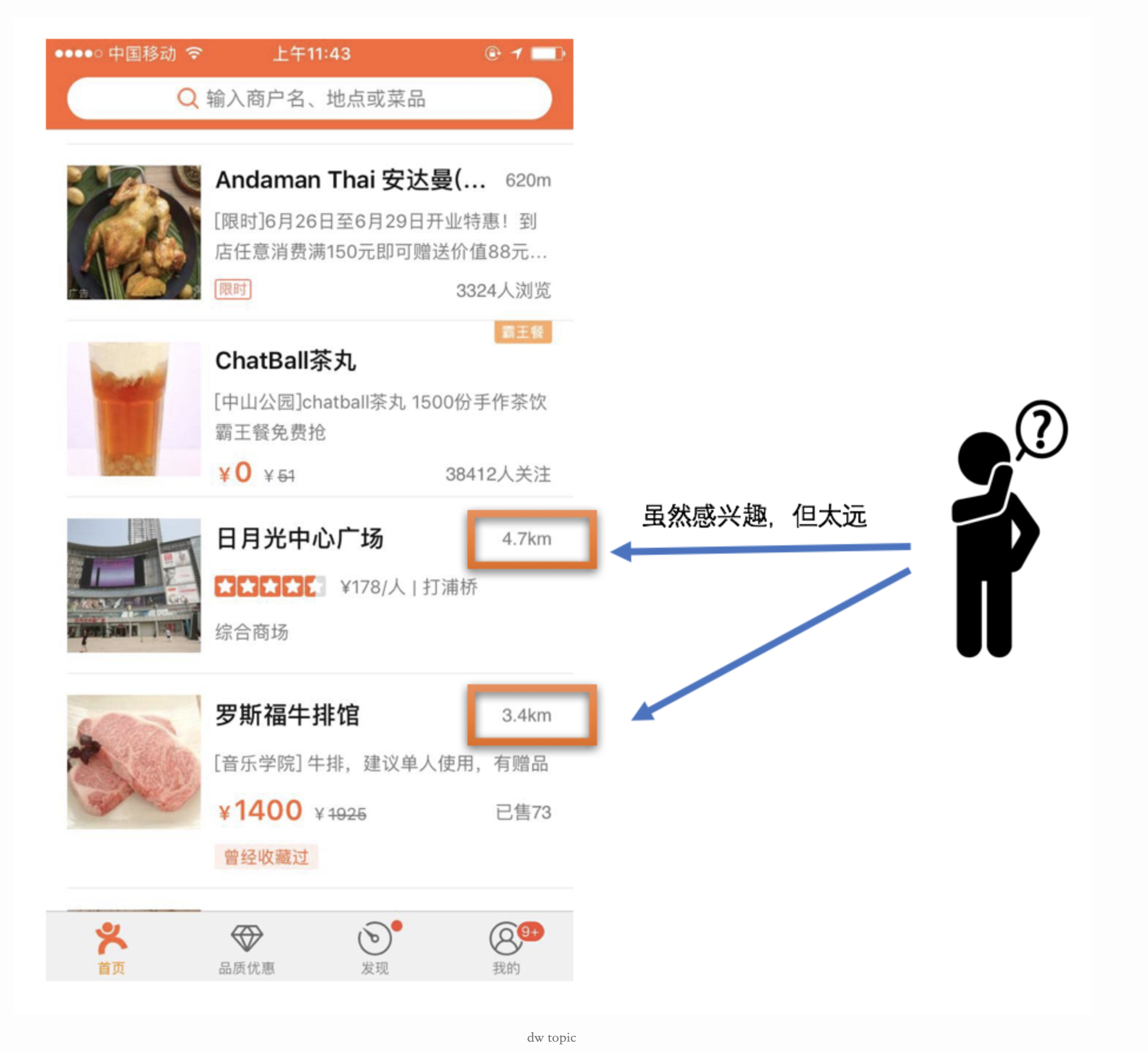
从图中我们可以看到,系统在非常靠前的位置推荐了一些远距离的商户,因为这些商户曾经被用户点过,其本身点击率较高,那么就很容易被系统再次推荐出来。但这种推荐并没有结合当前场景给用户推荐出一些有新颖性的Item。为了解决这个问题,就需要考虑更多、更复杂的特征,比如组合特征来替代简单的“距离”特征。怎么去定义、组合特征,这个过程成本很高,并且更多地依赖于人工经验。
所以说线性模型严重依赖于特征工程,通过特征工程提高推荐的新颖度,需要大量的人工操作。
而深度神经网络,可以通过低维密集的特征,学习到以前没出现过的一些Item和特征之间的关系,并且相比于线性模型大幅降低了对于特征工程的需求,从而吸引我们进行探索研究。
在实际的运用当中,美团根据Google在2016年提出的Wide & Deep Learning模型,并结合自身业务的需求与特点,将线性模型组件和深度神经网络进行融合,形成了在一个模型中实现记忆和泛化的宽深度学习框架。在接下来的章节中,将会讨论如何进行样本筛选、特征处理、深度学习算法实现等。


样本筛选
数据及特征,是整个机器学习中最重要的两个环节,因为其本身就决定了整个模型的上限。点评推荐由于其自身多业务(包含外卖、商户、团购、酒旅等)、多场景(用户到店、用户在家、异地请求等)的特色,导致我们的样本集相比于其他产品更多元化。我们的目标是预测用户的点击行为。有点击的为正样本,无点击的为负样本,同时,在训练时对于购买过的样本进行一定程度的加权。而且,为了防止过拟合/欠拟合,我们将正负样本的比例控制在10%。最后,我们还要对训练样本进行清洗,去除掉Noise样本(特征值近似或相同的情况下,分别对应正负两种样本)。
记笔记:正负样本的比例控制在10%就可以了!
同时,推荐业务作为整个App首页核心模块,对于新颖性以及多样性的需求是很高的。在点评推荐系统的实现中,首先要确定应用场景的数据,美团的数据可以分为以下几类:
- 用户画像:性别、常驻地、价格偏好、Item偏好等。
- Item画像:包含了商户、外卖、团单等多种Item。其中商户特征包括:商户价格、商户好评数、商户地理位置等。外卖特征包括:外卖平均价格、外卖配送时间、外卖销量等。* * 团单特征包括:团单适用人数、团单访购率等。
- 场景画像:用户当前所在地、时间、定位附近商圈、基于用户的上下文场景信息等。
排序是一个非常经典的机器学习问题,实现模型的记忆和泛化功能是推荐系统中的一个挑战。记忆可以被定义为在推荐中将历史数据重现,而泛化是基于数据相关性的传递性,探索过去从未或很少发生的Item。宽深度模型中的宽线性部分可以利用交叉特征去有效地记忆稀疏特征之间的相互作用,而深层神经网络可以通过挖掘特征之间的相互作用,提升模型之间的泛化能力。在线实验结果表明,宽深度模型对CTR有比较明显的提高。同时,我们也在尝试将模型进行一系列的演化:
- 将RNN融入到现有框架。现有的Deep & Wide模型只是将DNN与线性模型做融合,并没有对时间序列上的变化进行建模。样本出现的时间顺序对于推荐排序同样重要,比如当一个用户按照时间分别浏览了一些异地酒店、景点时,用户再次再请求该异地城市,就应该推出该景点周围的美食。
- 引入强化学习,让模型可以根据用户所处的场景,动态地推荐内容。
总的来说,美团的排序模型就是Wide & Deep咯,虽说我们都知道什么是wide & deep 但是放到具体地业务中,还是有许多坑要填的,尽管这篇文章有一些召回的细节没有透露,但是还是干货满满,感谢!