我们首先考虑离散随机变量 x 当我们观察到该变量的值时候,我们可以将信息量视为x 值的"惊喜程度". 如果我们被告知刚刚发生了一个非常不可能的事件,我们将收到的信息比我们被告知刚刚发生了一些非常可能发生的事件的情况要多,如果我们知道该事件肯定会发生,我们将不会收到任何信息.因此,我们对信息内容的测量将取决于概率p(x), 因此我们要寻找一个函数h(x),它是p(x)的单调函数,表示信息内容.h(⋅)形式可以是:如果我们有两个不相关的事件 x 和 y,那么两者的信息应该是分别获得信息的总和,即
h(x,y)=h(x)+h(y)
但是两个不相关的时间在统计意义上是相互独立的,也就是
p(x,y)=p(x)p(y)
从这两个关系中,很容易证明h(x)是由p(x)的对数形式给出,因而我们有:
h(x)=−log2p(x)
负号确保信息为小于等于0的数字。当低概率事件x对应于高信息内容.对数的底的选择的,目前我们使用以2为底的对数,这里仅仅是方便表达.我们获得信息熵的期望
H[x]=−x∑p(x)log2p(x)
这个重要的量被称为随机变量 x 的熵.值得一提的是我们人为规定当 p 等于0的时,linp→0lnp=0.此外,非均匀分布的熵小于均匀分布的熵,具体为什么参见后面.
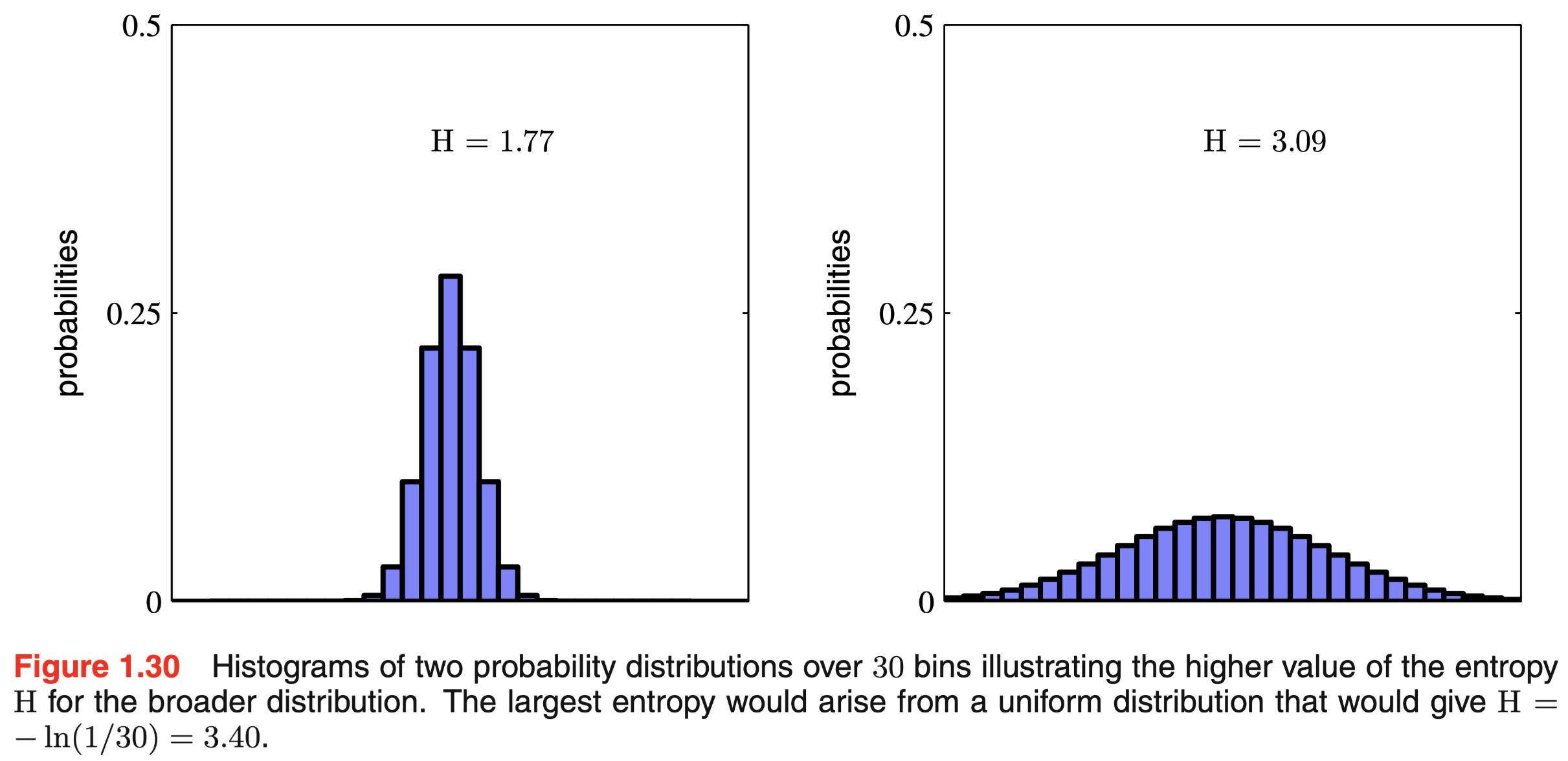
两个不同概率分布的 p 说明了较均匀的分布会有更高的信息熵的期望
由于0≤pi≤1熵是非负的,极端的情况是其中一个pi=1,其他pj=0时,信息熵的期望为最小值0.熵的期望最大值可以通过使用拉格朗日乘子法强制对概率进行归一化约束,优化函数为:
H^=−i∑p(xi)lnp(xi)+λ(i∑p(xi)−1)
从公式中我们可以看出所有的p(xi)是相等的,且都等于M1其中,M 为 x 所有可能的取值个数.对应熵的期望最大值是 H=lnM这个公式也可以利用 Jensen 不等式推出,为了验证M1的确是函数的最大值,我们可以计算熵的二阶导函数,也就是:
∂p(xi)∂p(xj)∂H^=Iijpi1
我们可以拓展信息熵的定义,将分布p(x)考虑为联系变量,我们首先把 x 划分为宽度为Δ的区间,然后假设p(x)是连续的,那么我们可以使用均值定理.对于每一个区间我们存在一个变量 x 使得
∫iΔ(i+1)Δp(x)dx=p(xi)Δ
我们现在可以将任何值赋值给x只要该值在区间范围内.对应的观察值为p(xi)Δ这给出了采用熵的形式离散分布:
HΔ=i∑p(xi)Δln(p(xi)Δ)=−i∑p(xi)Δln(p(xi)−lnΔ)
在上述公式中,我们有∑ip(xi)=1, 当Δ→0我们忽略第二个项−lnΔ我们有:
Δ→0lim{i∑p(xi)Δlnp(xi)}=−∫p(x)lnp(x)dx
其中等号右边被称作微分熵.对于多个连续变量上定义的密度, 我们用向量 x 来表示,差分熵的公式为:
H[x]=−∫p(x)lnp(x)dx
在离散分布的情况下,我们看到最大熵期望对应于等概率的均匀分布,首先和离散数据相同,我们有三个约束
∫−∞∞p(x)dx=1
∫−∞∞xp(x)dx=u
∫−∞∞(x−u)2p(x)dx=σ2
我们对这三个公式引入拉格朗日乘子法,得到关于p(x)的公式:
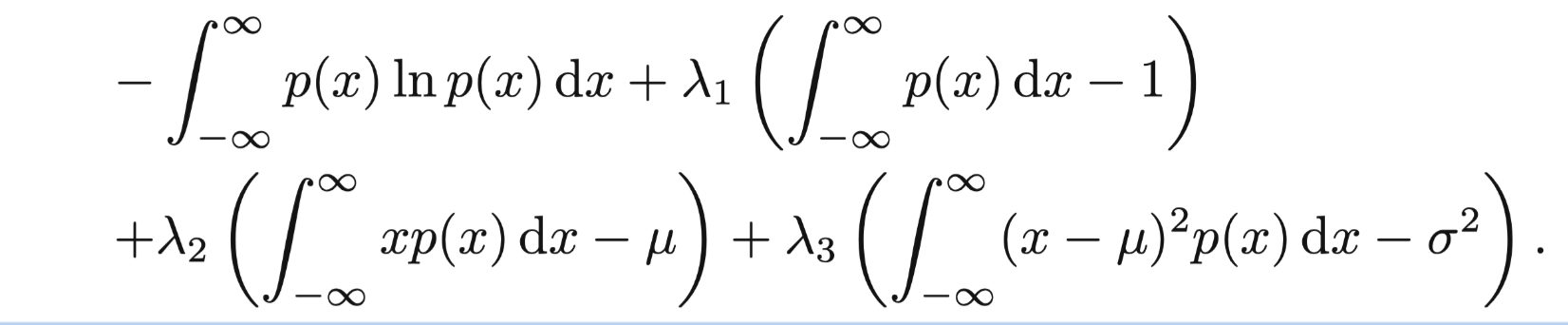
我们令偏导数为0, 得到:
p(x)=exp{−1+λ1+λ2x+λ3(x−u)2}
最终我们获得结果:
p(x)=(wπσ2)1/21exp{−2σ2(x−u)2}
因此我们获得最大化连续熵对应的分布式高斯分布,对应的最大值为
H[x]=21{1+ln(2πσ2)}
我们发现随着σ2变大,信息熵的期望也会越来越大.与离散熵不同,微分熵可以是负的:当σ2<1/(2πe)时, 我们有H(x)<0
相对熵与互斥信息
假设我们有一个未知的分布p(x),假设我们有一个近似分布q(x). 如果我们使用q(x)来构造编码方案,以便把 x 的值发送给接收方.然而我们使用的是分布q(x),而不是真实的p(x)来指定 x 的编码值,所需的平均附加信息量为:
KL(p∣∣q)=−∫p(x)lnq(x)dx−(−∫p(x)lnp(x)dx)
=−∫p(x)ln{p(x)q(x)}
(大名鼎鼎的 KL 散度),注意相对熵不是对称的,换句话说KL(p∣∣q)≠KL(q∣∣p)
当且仅当p(x)=q(x)时,我们有KL(p∣∣q)≥0
Jesen 不等式的推导
Jesen不等式来源于凸函数的推导,我们有:
f(λa+(1−λ)b)≤λf(a)+(1−λ)f(b)
由此得到Jesen 不等式:
f(i=1∑Mλixi)≤i=1∑Mλif(xi)
对于任何一个组点{xi}我们有λi≥0和∑iλi=1如果我们把λk看成连续分布变量(而不是离散变量取值{xi}),我们有:
f(E[x])≤E[f(x)]
对于连续变量,Jesen 不等式的推导为:
f(∫xp(x)dx)≤∫f(x)p(x)dx
我们把 Jesen 不等式带入到 KL 散度中,我们有
KL(p∣∣q)=∫p(x)ln{p(x)q(x)}≥−ln∫q(x)dx=0
其中lnx是一个凸函数,∫q(x)dx=1. 当且仅当p(x)=q(x)时,有等式成立.因此我们用 Jesen不等式来解释 KL 散度作为分布 p(x)和分布 q(x)的相似性度量.
我们假设数据分布是从未知分布p(x)生成的,我们可以尝试使用一些参数θ建模q(x∣θ)以近似该分布,其中θ参数是可以自行调整的(如多元高斯分布).对数决定θ我们可以考虑最小化p(x)和q(x∣θ) 之间KL的散度来优化模型.但是我们不能直接获得 p(x),因此我们假设我们观察到一些有限的从 p(x)中抽样的数据训练点xn,利用数据点的来有限近似p(x)的期望.
KL(p∣∣q)≃n=1∑N{−lnq(xn∣θ)+lnp(xn)}
公式右面的第二项与θ无关,第一项是使用训练集评估的分布q(x∣θ),可以看到最小和 KL 散度等价于最大化极大似然函数.
对于独立变量 x 和 y 那么我们有p(x,y)=P(x)p(y), 但是如果变量本身不是独立的,我们可以考虑查看联合分布与概率乘积之间的 KL 散度来观察它们是否真正独立:
I[x,y]=KL(p(x,y)∣∣p(x)p(y))=−∫∫p(x,y)lnp(x,y)p(x)p(y)dxdy
这被称为变量 x 和 y 之间的互信息.从 KL 散度的性质来看,只有当x 和 y 独立时, 才等于0.基于概率的和与乘积规则,我们可以看到互信息和条件熵有关.
I[x,y]=H[x]−H[x∣y]=H[y]−H[y∣x]
因此我们可以利用互信息可以做到通过观察变量 y 来减少 x 的不确定性.从贝叶斯的角度看,我们可以把 p(x)看成先验分布,将 p(x|y)看成后验分布.因此,像是信息由于观察到 y 而导致 x 的不确定性降低.