Abstract 本文的贡献是在传统的word2vec基础上,为了减轻数据系数和冷启动问题,将辅助信息和合并到图embedding框架中。为了将辅助信息合并到图embedding中,本文提出了两种方法,离线的实验结果表明包含了辅助信息 去看看~
月度归档: 2019年7月
面试时候需要做的准备(持续更新~)
快速排序 class Solution { public: const int N = 1e6+10; void quickS(int l, int r, vector &v) { if(l >= r) return; int mid = v[l], i = l - 1, j = r + 1; while(i < j) { do i++; while(v[i] < mid); do j-- 去看看~
Hadoop+Hbase+Zookeeper+Mahout全平台搭建教程
加载需要一些时间(大约11Mb),请耐心等待 [pdf-embedder url="https://goesbest.cn/wp-content/uploads/2019/07/hadoop.pdf"] 去看看~
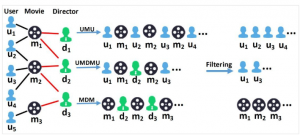
密码保护:Embedding跨领域推荐想法记录
无法提供摘要。这是一篇受保护的文章。